Taller de ingeniería: Recreamos la guerra de Ahn’Qiraj
La guerra se avecina. A principios de este mes, se lanzó uno de los eventos más anticipados de World of Warcraft: Classic, la guerra de Ahn’Qiraj. Reinos enteros de Classic, el poderío combinado de la Horda y la Alianza, se unieron y sumaron sus recursos para abrir las puertas y desbloquear las bandas de Ahn’Qiraj. Cuando se llevó a cabo la guerra del Mar de Dunas por primera (y única) vez en 2006, miles de jugadores de todos los reinos volaron o galoparon a Silithus para participar en el caos o para verlo. La participación fue mucho mayor de lo que el equipo de desarrollo se imaginaba. En pocas palabras, no estábamos preparados. Los servidores se sobrecargaron rápidamente y muchos jugadores quedaron atrapados en el ciclo sin fin de iniciar sesión, sufrir una desconexión e intentar conectarse de nuevo durante unas 12 horas. Mientras tanto, nuestros ingenieros se esforzaban por corregir errores para que los jugadores pudieran conectarse. Si bien logramos estabilizar los servidores durante el evento y aprendimos algunas lecciones, entendimos que había espacio para mejorar. Quince años después, estábamos listos para recrear uno de los momentos más épicos de la historia de WoW para WoW Classic enfocándonos en la optimización de los servidores para combatir el lag y eliminar las interrupciones de los servidores, todo esto con el doble de jugadores en Silithus de los que había en el evento de 2006.
En este artículo, te mostraremos cómo hicimos para recrear este evento tan ansiado con jugadores automatizados y pruebas de estrés para determinar los puntos de inflexión y las soluciones manuales de optimización, cómo ideamos soluciones del software para resolver problemas que el hardware no podía resolver, y cómo albergamos un evento mundial con pocos errores de servidores, manteniendo intacta la experiencia de juego de WoW Classic.
La recreación de la segunda guerra del Mar de las Dunas
Teníamos tres objetivos específicos cuando preparamos este evento: Evitar las interrupciones del servidor, aumentar los límites de juego esperados y determinar cuánto lag era tolerable antes de sacar a los jugadores de Silithus. Antes de explicar lo que hicimos para optimizar el funcionamiento del servidor, es importante entender los problemas que enfrentábamos: las limitaciones de la base de código de WoW Classic, el modo de gestionar la población y el modo en que estas afectan a la experiencia de juego.
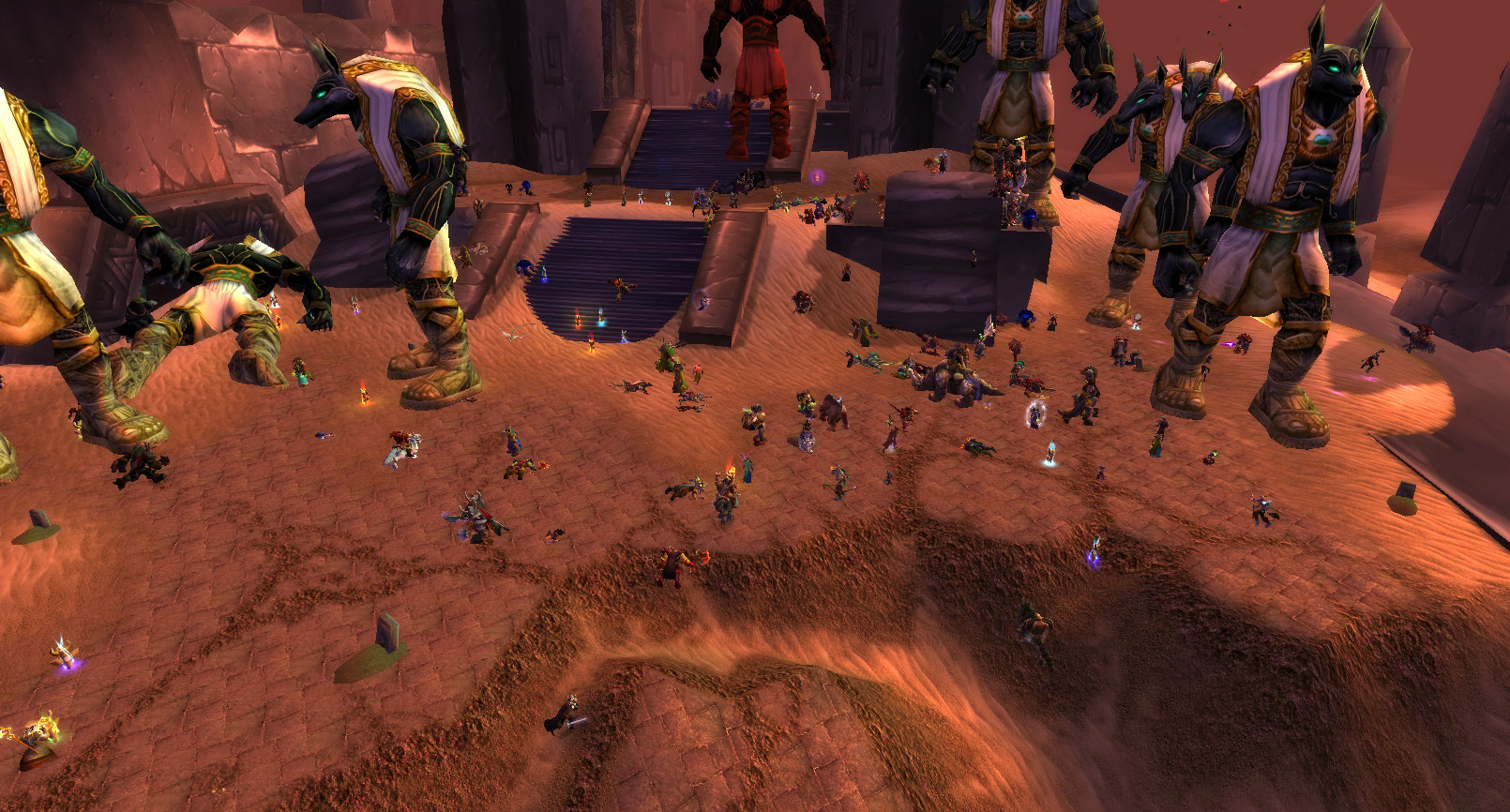
Más allá de los límites
La versión moderna de World of Warcraft se construyó sobre la base de código que se lanzó hace 15 años. Desde el lanzamiento del juego, hemos desarrollado formas más modernas de administrar una gran cantidad de jugadores en Battle for Azeroth, entre ellas, el sharding. La tecnología de sharding permite que los servidores WoW puedan albergar muchos más jugadores en el juego de lo que era posible en 2006. En Battle for Azeroth, utilizamos esta técnica para gestionar la carga de jugadores de los servidores creando una copia de una zona (por ejemplo, Zuldazar) una vez que la cantidad de jugadores alcanza el umbral. Esto neutraliza los problemas de lag, ya que reparte a los jugadores en diferentes versiones de la zona. Esto se debe a que las interacciones entre jugadores son las que requieren más poder de procesamiento por la cantidad de datos que envían de manera constante al servidor para mejorar la precisión de sus movimientos y lanzamientos de hechizos. Además, el sharding evita los errores potenciales de lag que se pueden encontrar mientras recorres una nueva zona donde el número de jugadores ha superado el umbral. No parece difícil, pero hay una trampa, porque WoW Classic se creó con el objetivo de ser fieles al tamaño original del parche 1.12, lo cual incluye conservar sus peculiaridades. En pocos casos, el sharding puede ocasionar que tu presa, como un jugador enemigo o un PNJ, desaparezca cuando van a otra zona. El uso de sharding implica perder algo de la nostálgica experiencia de juego de perseguir jugadores o PNJ a lo largo de los límites de una zona. Por eso, necesitábamos encontrar una solución que no interfiriera con la experiencia de juego original y que, al mismo tiempo, nos permitiera admitir más jugadores en el servidor sin que otros jugadores tengan que sufrir un lag insoportable.
Para resolver este problema, decidimos usar capas, copias completas de regiones (por ejemplo, los Reinos del Este), para controlar los problemas de número de jugadores y de lag, y al mismo tiempo, mantener el encanto del juego original intacto para que los jugadores puedan pelear contra jefes a lo largo de las zonas y perseguir jugadores enemigos hasta los límites de una región sin correr el riesgo de que se los reasigne mediante el sharding. Sin embargo, las capas se diseñaron como una solución temporal. Dado que el parche original 1.12 no tenía ninguna de las tecnologías de sharding o capas, prometimos a los jugadores que solo usaríamos las capas durante el lanzamiento de WoW Classic y que las iríamos eliminando de a poco a medida que ellos fueran dispersándose a lo largo del mundo. Hay unos pocos casos en los que todavía usamos las capas debido a la inmensa cantidad de jugadores (por ejemplo, Faerlina de Norteamérica), pero hemos reducido la cantidad de capas activas en estos reinos desde el lanzamiento del juego. Después de 15 años de espera, la guerra de Ahn’Qiraj es uno de los eventos más ansiados de WoW Classic, y esperamos que tenga la mayor cantidad de jugadores sin necesidad de usar capas en un área que no sea la zona inicial durante el lanzamiento del juego. Sin las tecnologías de capas o sharding, tuvimos que ponernos creativos en muy poco tiempo.

Una experiencia inolvidable hecha a mano
La búsqueda de una solución que no signifique usar capas o sharding empezó con el uso de jugadores automatizados, a los que se les instruyó que hicieran lo que harían los jugadores reales: lanzar hechizos, pelear contra PNJ y moverse en toda el área. Esto nos permitió hacernos una idea de lo que sería el desempeño con miles de jugadores interactuando en una única área. Después de realizar estos simulacros, organizamos pruebas de estrés con voluntarios para observar comportamientos realistas de jugadores y compararlos con los datos previos. Esto nos permitió ubicar algunos puntos de inflexión y saber qué partes del código de nuestro servidor tendrían más problemas ante grandes cantidades de jugadores. Las mediciones de FPS del servidor se evaluaron cuidadosamente para ver cuán cerca estaban de ocasionar una interrupción del servidor, lo que se conoce también como interbloqueo.
El siguiente paso fue analizar qué era lo que afectaba el funcionamiento del servidor para poder dividir esta tarea monumental en objetivos más pequeños. Nos enfrentamos a un problema de polinomios, es decir, no podíamos solucionarlo con hardware más rápido porque el hardware no era exponencialmente mejor. En su lugar, tuvimos que hacer a mano la optimización escogiendo deliberadamente los datos que se comunicarían a los jugadores y con qué frecuencia. Para ilustrar este problema, supongamos que tenemos 20 jugadores saltando en ronda. El servidor transmite las acciones de cada jugador a los otros 19 a través de paquetes (datos listos para entregar). En este grupo de 20, el servidor procesa 380 paquetes (20 jugadores en total * 19 receptores = 380 paquetes). Este problema es peor cuando hay más jugadores haciendo una misma acción en la zona. Si aumentamos nuestro ejemplo a 500 jugadores, se envían 249 500 paquetes desde el servidor. Y si lo aumentamos a 1 500 jugadores, son 2 248 500 los paquetes que se envían. Según las acciones de los jugadores, se envían muchos paquetes por segundo (ten en cuenta que en los ejemplos anteriores hablamos solo de una acción). Cuantos más paquetes se envíen al servidor, mayor será el tiempo de procesamiento que el servidor necesita para un solo jugador para luego encargarse de las acciones de todos los demás jugadores. Cuando el problema se agrava, los servidores se acercan a un interbloqueo. En WoW Classic, tenemos muchos más jugadores por reino de los que teníamos en 2006, de modo que esperamos albergar a más jugadores que antes alrededor de las puertas.
Optimizar el funcionamiento del servidor
Nuestros servidores están diseñados para interrumpirse y reiniciarse cuando hay un interbloqueo, por eso sabíamos que era muy importante hacer todo lo que estuviera a nuestro alcance para minimizar el tiempo de procesamiento. Luego de algunas pruebas, vimos que el procesamiento del movimiento era lo que más estaba cargando a los servidores. Empezamos por dejar de lado las actualizaciones de orientación (mostrar la dirección hacia la que mira el modelo de un personaje) para enviar a los jugadores solo las actualizaciones cuando alguien empieza a moverse, se detiene o usa el movimiento por teclado. Ya con el hecho de tener una gran cantidad de jugadores, la latencia se ve afectada, por lo que utilizar tiempo de procesamiento para enviar actualizaciones menores de orientación empeoraba la fidelidad. Era mejor dejar de enviarlas. Tomamos la decisión de enviar actualizaciones de movimiento menos seguido para poder tener más jugadores en una zona. Ten en cuenta que estábamos buscando el punto de quiebre antes de que los servidores cayeran mientras permitíamos la entrada de la mayor cantidad de jugadores posible en Silithus. Después de todo, es preferible perderse algunas actualizaciones de movimiento que no poder ingresar con tu personaje. También empezamos a regular los datos marcados como de baja prioridad. Una acción considerada “menos importante” no debería enviarse con la misma frecuencia que una “más importante”. Vimos que se enviaban muchos mensajes al mismo tiempo sin que se tuviera en cuenta su importancia, entonces optimizamos el código para enviar la información menos importante en lotes y con menor frecuencia.
Los beneficios y los perjuicios eran otra cosa importante a tener en cuenta en el desempeño de los servidores. En todo el mundo, especialmente luchando contra criaturas, se aplican beneficios y perjuicios todo el tiempo. Si bien no pareciera ser la gran cosa, se trata de información que tiene que circular entre una gran concentración de jugadores. Hicimos algo similar que con los datos de baja prioridad: agrupamos los beneficios y perjuicios en lotes para no enviar muchos paquetes sucesivamente.
Gestionar la cantidad de jugadores
Además de optimizar los servidores para que pudieran soportar más jugadores en cada zona, no perdimos de vista que sería imposible hacer que entraran todos los jugadores del reino (más del doble de lo que admitía originalmente el reino de WoW 1.12) en Silithus. Tuvimos que tomar decisiones difíciles para limitar el acceso a la zona y controlar a quién le permitíamos entrar y a cuántos podríamos albergar. Decidimos que solo tendrían acceso a Silithus los personajes de nivel 60 y que no podrían entrar más jugadores cuando se llenara. Esta restricción fue la decisión correcta, ya que el evento de Silithus es un contenido avanzado, y los personajes de bajo nivel podían participar de la campaña de guerra en otras zonas derrotando a los anubisath que rondan por Los Baldíos, algo pensado para jugadores de nivel 20 a 30. El otro problema era que, si bien sabíamos cuál era el límite máximo de jugadores que podía haber en un área sin que se interrumpiera el servidor, teníamos que decidir a cuánto había que reducir ese número para lograr el mejor balance entre un buen funcionamiento y la cantidad de jugadores. Luego de algunas pruebas, llegamos a la conclusión de que ese número era de unos 1 500 jugadores, apilados uno sobre el otro. Sin embargo, como el evento sucede en toda la zona, vimos que había muy pocos problemas de funcionamiento cuando los jugadores se separaban.
El evento se planificó para que tuviera lugar en todas las regiones, por lo que teníamos que asegurarnos de que funcionara en muchas capas. Esto quiere decir que cuando un jugador con el cetro golpeara el gong en una capa, el evento debía comenzar en todas las otras capas conectadas a ese reino. Como el evento se activa con una interacción de un jugador, queríamos asegurarnos de que quien portara el cetro fuera visible en todas las capas para que todos los jugadores del mismo reino pudieran verlo. Esto generó un problema interesante, ya que los servidores ahora tenían que transmitir información que normalmente no necesitarían comunicar. Esta cuestión podría traer varias complicaciones cuando compilamos y enviamos actualizaciones a través de los servidores para asegurarnos de replicar la información en varias capas y enviarla potencialmente a miles de jugadores.
Empezamos a desarrollar esta tecnología con la introducción del Torneo de pesca de Tuercespina y luego la aplicamos para los beneficios de mundo de Onyxia, Nefarian, Zul’garub, y Rend. Cuando vimos que funcionaba como nos lo propusimos, ya estábamos preparados para probar esa tecnología junto con los otros desarrollos para el evento de la campaña de Ahn’Qiraj.
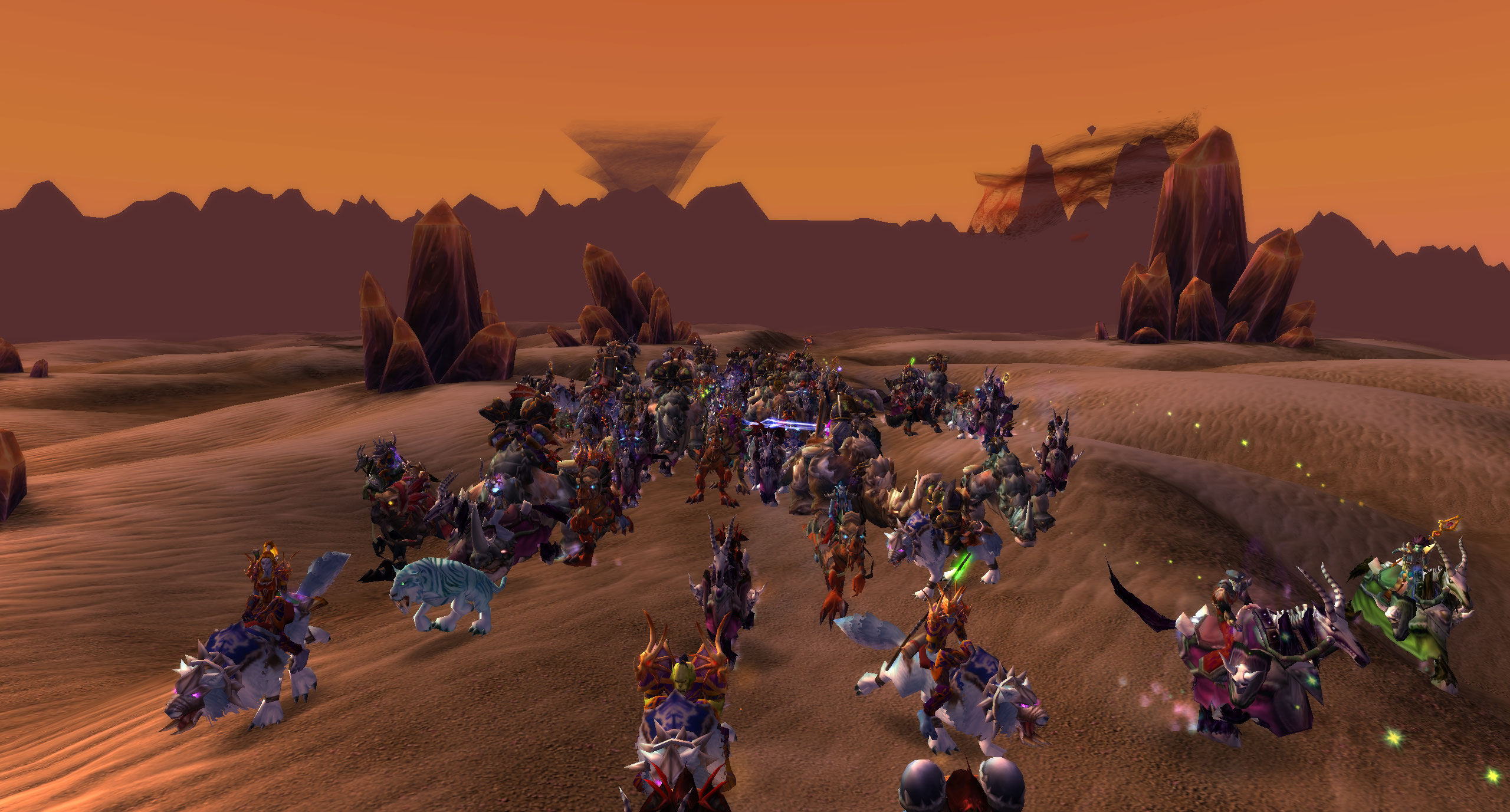
Experimentar con soluciones
Una vez que superamos los obstáculos técnicos e implementamos varias formas de optimizar el funcionamiento de los servidores, llegó el momento de poner a prueba nuestro trabajo. La guerra dura 10 horas, y creamos una versión a escala de una hora de duración.
En la primera prueba de estrés, dejamos entrar a casi todos los jugadores a la zona para ver qué sucedía. En un punto, llegamos casi a un 150% de la capacidad de todo un reino de 1.12. Ahí fue cuando nuestro reino de prueba sufrió una interrupción. Sabíamos que habíamos establecido una cantidad máxima de jugadores muy alta para la zona, y veíamos cifras que excedían ese límite por mucho. Investigamos el problema y descubrimos que el código que permitía que los jugadores vayan entraran y salieran de una zona era una cola que no procesaba a muchos jugadores al mismo tiempo. Es por eso que no se teletransportaba a los jugadores para salir y también era la causa de que algunos estuvieran trabados en rutas de vuelo durante un tiempo inusualmente extenso. Restauramos el servidor y continuamos la prueba de estrés haciendo ajustes sobre la marcha. Fuimos reduciendo el número de a poco hasta un punto en el que había un poco de lag, se podía jugar medianamente bien y había una cantidad de jugadores mucho mayor a la que cualquier otra zona haya albergado antes. El evento estaba pensado para completarse en una hora y media, pero se tardó hasta cuatro horas debido a las interrupciones.
Realizamos la segunda prueba de estrés una semana más tarde, lo que nos permitió ver si nuestras optimizaciones funcionaban. Al ingresar a la prueba, notamos mejoras de inmediato: ¡los jugadores ya no se trababan en rutas de vuelo hacia Silithus! Pudimos obtener suficiente información para saber cuántos personajes podíamos albergar cómodamente en Silithus. Luego de estas dos pruebas, avanzamos con los números que creíamos que ofrecían el mejor equilibrio entre el lag y la estabilidad del servidor. Estas pruebas nos permitieron ver si nuestras optimizaciones cumplían con su propósito, y consideramos que fueron exitosas porque nos permitió identificar los límites de las zonas y replicarlos.
Llevar las soluciones a los servidores por todo Azeroth
Originalmente habíamos pensado usar estas optimizaciones solo para Silithus durante la guerra del Mar de Dunas. Luego de ver que sería seguro usarlas globalmente, las aplicamos a todo el mundo en 1.13.5. Una vez iniciada la campaña de guerra, los jugadores comenzaron a entregar suministros y a escarbar cadáveres de insectos en forma masiva. Vimos un gran incremento en la cantidad de jugadores, no solo en Silithus, sino también en nuestras ciudades capitales y las afueras. Con estas optimizaciones logramos que hubiera un buen rendimiento durante estas experiencias y que pudieran realizarse grandes batallas JcJ por todo Azeroth. Algunos jugadores hasta hicieron aparecer a Thunderaan para eliminar de una colmena a la otra facción.
Hubo algunos problemas extraños en algunos servidores por el cual la campaña de guerra no progresaba aun cuando no había empezado el evento de la apertura de las puertas. El ritmo al que algunos servidores completaban su campaña de guerra era tan rápido que causaba una condición de carrera en la lógica de cada entrega que podía impedir que comenzara el conteo de cinco días. Dado que la probabilidad de que sucediera este caso extremo era muy baja, pudimos arreglar esos servidores manualmente y luego resolver este problema en los siguientes servidores que estuvieran completando su campaña.
Una vez completadas las campañas de guerra y transcurridos los cinco días para abrir las puertas, comenzamos a monitorear los reinos chinos que fueron los primeros del mundo en abrirlas. El primer servidor de China donde se activó un gong fue Ouro. Mientras monitoreábamos la cantidad de jugadores en las capas, vimos que la mayoría, en cada capa, estaba en Silithus. Nunca habíamos hecho que el evento empezara en muchas capas que estaban a su máxima capacidad para varios miles de jugadores al mismo tiempo. Si bien parecía haber algo de lag, nuestros servidores no se interrumpieron durante la apertura del primer grupo de reinos de China.
Golpear el gong
Notamos que el 4 de agosto habría varios reinos de América del Norte listos para golpear el gong poco tiempo después de un reinicio de servidores. Monitoreamos activamente estos reinos uno por uno en cuentas de maestro de juego y con nuestras herramientas de observación para solucionar cualquier problema con el que nos encontráramos. En todos los reinos se abrieron las puertas y el evento empezó sin problemas. Los portadores del cetro recibieron sus prestigiosas monturas de Tanque de batalla qiraji negro, los jugadores pudieron luchar contra insectos aún más grandes, y estábamos satisfechos con la estabilidad. Mientras esperábamos a que terminara el período de cinco días en los primeros servidores luego del reinicio, notamos un problema grave: los eventos no continuaban luego de los reinicios de servidores. Esto quiere decir que si un servidor caía o se reiniciaba, se perdía todo el progreso del evento. Si bien este problema existió desde el comienzo del desarrollo de WoW Classic, no había habido muchos casos en los que los eventos perduraran después de los reinicios de servidores. Nuestro equipo pudo resolver el problema rápido, pero teníamos que asegurarnos de que no ocurrieran más reinicios hasta poder implementar una corrección y catalogar debidamente el estado de todas las campañas en curso en nuestra base de datos sin interrumpir a los jugadores.
Hay quienes dicen que permitir que los servidores cayeran es lo que hizo que la guerra original de Ahn’Qiraj fuera un caos, lo que a su vez la hizo memorable. En esta ocasión, queríamos despertar esa misma pasión generando una experiencia más cuidada y estable para que pudieran compartirla 1 500 jugadores en Silithus al mismo tiempo en cada servidor. Queríamos que la guerra de Ahn’Qiraj de Classic fuera recordada como el evento de 10 horas sin interrupción con la mayor cantidad de jugadores posible. Si bien hubo interrupciones en algunos reinos, pudimos levantarlos rápidamente. Los recuperamos por completo y logramos ponerlos en línea en minutos y no sufrieron más interrupciones.
Más de 4 000 jugadores en todo el mundo se han convertido en Señores Escarabajo, y son cada vez más a medida que progresan las campañas de guerra en cada servidor. Ha sido increíble ver la emoción que provoca Classic desde que comenzó la campaña de guerra de Ahn’Qiraj, y estamos muy agradecidos con todos los que se unieron a la segunda guerra del Mar de Dunas.